Introduction
Modern enterprise infrastructure requires robust systems that can handle scale, velocity, and unpredictable failure modes. The Certified Site Reliability Engineer program bridges the gap between traditional software development and IT operations by instilling a production-first mindset. This comprehensive guide is designed for engineering professionals, infrastructure specialists, and engineering managers who want to validate their operational expertise and drive systemic resilience across cloud-native environments. Navigating the evolving landscapes of DevOps, platform engineering, and modern infrastructure requires structured validation, which this blueprint provides to help you make informed career investments. Understanding these structured pathways helps you align engineering efforts with business outcomes while mastering complex distributed architectures, with foundational insights supported by platforms like sreschool and specialized domains such as aiopsschool.
What is the Certified Site Reliability Engineer?
The Certified Site Reliability Engineer designation represents a rigorous framework designed to validate an engineer’s ability to design, build, and run highly available distributed systems. It exists because theoretical knowledge falls short when production systems face real-world degradation, cascading failures, or sudden traffic spikes. This program emphasizes practical, hands-on engineering principles derived from large-scale production environments rather than abstract methodologies or rigid software theories.
By focusing on production-grade realities, the curriculum addresses how modern systems interact with automated infrastructure, continuous delivery pipelines, and complex telemetry networks. It aligns closely with the daily workflows of enterprise environments where downtime directly impacts business revenue and customer trust. Engineers who undergo this validation demonstrate proficiency in balancing feature velocity with systemic stability, ensuring that operational guardrails are baked directly into the software development lifecycle.
Who Should Pursue Certified Site Reliability Engineer?
This program benefits software engineers who want to specialize in infrastructure resilience, as well as cloud, platform, and DevOps professionals aiming to deepen their operational capabilities. Security specialists and data engineers also gain immense value by learning how to apply reliability principles to high-throughput data streams and secure delivery pipelines. The framework accommodates diverse career stages, providing clear baselines for junior engineers while offering advanced architectural tracks for senior leads.
From a leadership perspective, engineering managers and technical directors leverage this framework to establish a common operational language across their engineering departments. For professionals working within global delivery centers or localized enterprise hubs like India, this certification provides a standardized, globally recognized validation of skills. It enables engineers to stand out in competitive markets by demonstrating a verifiable ability to manage complex, multi-cloud production systems.
Why Certified Site Reliability Engineer
The demand for specialized reliability professionals continues to outpace supply as organizations migrate legacy systems to complex microservices and cloud-native topologies. This program offers longevity because it prioritizes core engineering principles—such as telemetry, error budgets, and post-mortems—over fleeting, tool-specific configurations. Software tools and deployment platforms change frequently, but the foundational mechanics of building resilient, self-healing systems remain constant across the industry.
Investing time and effort into this certification delivers a clear return by positioning professionals for high-impact roles that protect enterprise revenue. Organizations actively seek engineers who can quantify operational risks and eliminate manual intervention through systemic automation. This qualification serves as an objective indicator that an engineer can confidently own production availability and lead large-scale architectural transformations.
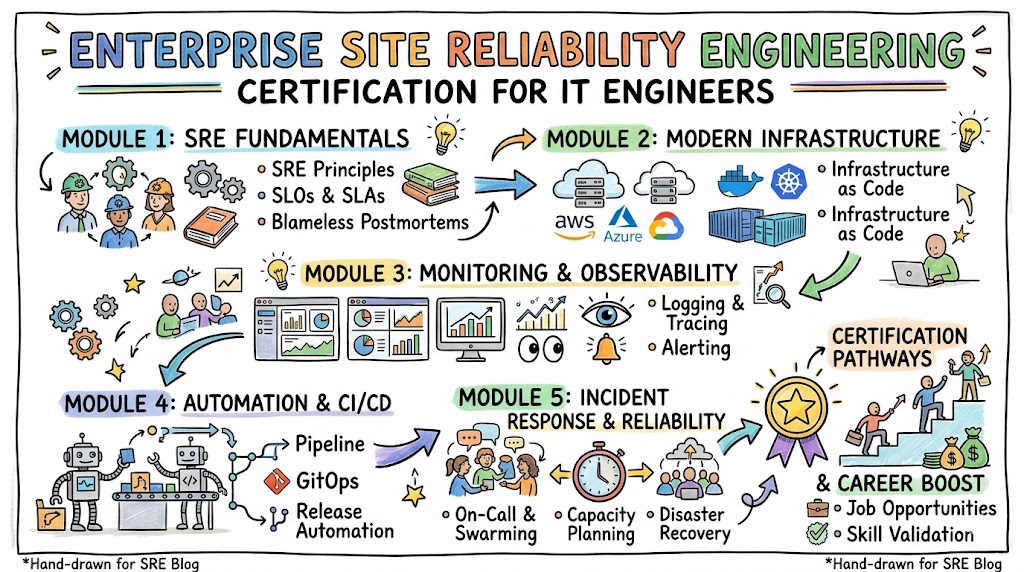
Certified Site Reliability Engineer Certification Overview
The structured program is delivered via the official training portals and hosted on the sreschool platform, which serves as the primary repository for the curriculum. The program features multiple certification levels, ensuring a progressive learning curve that validates both fundamental concepts and advanced architectural design. Assessment relies heavily on practical evaluation, requiring candidates to demonstrate problem-solving capabilities under simulated production constraints rather than simple rote memorization.
The framework is owned and updated by industry practitioners to ensure the content reflects contemporary engineering challenges and enterprise governance requirements. Structurally, the program is divided into modular components that allow professionals to study distinct operational areas at their own pace. This modular design makes it easy to integrate technical training into a full-time engineering schedule without disrupting daily deliverables.
Certified Site Reliability Engineer Certification Tracks & Levels
The certification roadmap is divided into three distinct tiers: Foundation, Professional, and Advanced, allowing candidates to build technical depth sequentially. The Foundation level focuses on core vocabulary, service level objectives, and basic monitoring techniques needed to participate effectively in on-call rotations. The Professional tier dives deep into automation, post-mortem analysis, and advanced deployment strategies like canary testing and progressive delivery.
The Advanced level addresses systemic architectural governance, disaster recovery orchestration, and cost-optimized infrastructure design across hybrid environments. Specialization tracks allow engineers to align their learning path with specific domains such as performance engineering, cloud-native security, or automated telemetry. This clear stratification ensures that your educational investment directly corresponds to your target tier in corporate engineering hierarchies.
Complete Certified Site Reliability Engineer Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core SRE | Foundation | Associate Engineers, System Administrators | Basic Linux and Networking | SLOs, SLIs, Basic Monitoring, Incident Response | 1 |
| Advanced SRE | Professional | DevOps Engineers, SREs, Mid-level Developers | 2+ Years Production Experience | Automated Remediation, Chaos Engineering, CI/CD | 2 |
| Architecture | Advanced | Principal Engineers, Infrastructure Architects | Professional Tier Certificate | Distributed Systems Design, Multi-Region DR, Capacity Planning | 3 |
Detailed Guide for Each Certified Site Reliability Engineer Certification
Certified Site Reliability Engineer – Foundation
What it is
This certification validates a foundational understanding of site reliability engineering principles, focusing on the core metrics and culture required to maintain service availability.
Who should take it
Systems administrators, junior developers, and support specialists looking to transition into modern operational roles and understand automated infrastructure mechanics.
Skills you’ll gain
- Defining and calculating Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
- Navigating modern observability stacks and interpreting basic system telemetry.
- Utilizing incident response frameworks and executing basic on-call runbooks.
Real-world projects you should be able to do
- Configure an integrated monitoring dashboard for a multi-service web application using standard metrics.
- Establish an actionable alerting matrix that distinguishes between critical system anomalies and non-urgent events.
Preparation plan
- 7–14 days: Review core definitions, vocabulary, and the structural differences between traditional operations and reliability engineering.
- 30 days: Spend time configuring basic telemetry dashboards and practicing simple log-parsing routines in a sandbox environment.
- 60 days: Take mock assessments, review practical troubleshooting scenarios, and finalize your understanding of error budget mathematics.
Common mistakes
- Focusing purely on tool-specific configurations instead of mastering the underlying architectural concepts and metrics.
- Neglecting the mathematical logic behind error budgets and how they influence deployment velocity.
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Professional
- Cross-track option: Cloud Infrastructure Specialist
- Leadership option: Technical Team Lead Foundation
Certified Site Reliability Engineer – Professional
What it is
This certification validates advanced competence in engineering automated solutions for system remediation, deployment safety, and proactive failure mitigation.
Who should take it
Mid-level DevOps engineers, systems engineers, and software developers responsible for managing mid-to-large scale cloud deployments and deployment pipelines.
Skills you’ll gain
- Implementing automated incident self-healing scripts and complex orchestration runbooks.
- Designing and executing structured chaos engineering experiments to discover hidden systemic vulnerabilities.
- Managing progressive delivery mechanisms including canary releases and blue-green deployments.
Real-world projects you should be able to do
- Build a fully automated rollback mechanism triggered automatically when production error budgets are breached.
- Design and execute a localized chaos engineering experiment that proves system resilience during database dependency failures.
Preparation plan
- 7–14 days: Study advanced automation patterns, continuous delivery integration strategies, and the mechanics of progressive exposure.
- 30 days: Build end-to-end pipelines in a test environment that incorporate automated testing, deployment, and rollback triggers.
- 60 days: Analyze real-world post-mortems, practice troubleshooting complex system failures, and review chaos testing frameworks.
Common mistakes
- Overcomplicating automation scripts, which introduces additional failure vectors into the production environment.
- Conducting chaos engineering experiments in live environments without setting up appropriate blast-radius controls.
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Advanced Architect
- Cross-track option: Advanced DevSecOps Practitioner
- Leadership option: Engineering Manager Professional
Certified Site Reliability Engineer – Advanced Architect
What it is
This certification validates an engineer’s capability to architect massive, multi-region distributed systems that remain highly resilient under extreme operational load.
Who should take it
Principal engineers, enterprise infrastructure architects, and technical directors who oversee global cloud footprints and cross-functional platform teams.
Skills you’ll gain
- Architecting multi-region, active-active distributed database systems with strict consistency and availability patterns.
- Formulating long-term capacity planning models using predictive machine learning algorithms and workload telemetry.
- Governing enterprise-wide disaster recovery strategies and complex cross-region failover automation.
Real-world projects you should be able to do
- Design a comprehensive, automated cross-region failover blueprint for a high-transaction e-commerce architecture.
- Create an enterprise-scale capacity planning engine that automatically scales cloud infrastructure based on seasonal historical data.
Preparation plan
- 7–14 days: Deep dive into distributed systems theory, consensus protocols, and advanced network routing architectures.
- 30 days: Model complex multi-tier system failure scenarios and document structural mitigation patterns for each layer.
- 60 days: Conduct extensive architectural reviews, solve advanced case studies, and validate your designs against cost and compliance guardrails.
Common mistakes
- Designing overly complex architectures that exceed the actual operational scale and budget of the business.
- Underestimating the impact of network latency and data synchronization lag across geographically separated cloud datacenters.
Best next certification after this
- Same-track option: Enterprise Platform Governance Elite
- Cross-track option: Principal FinOps Architect
- Leadership option: Director of Engineering Infrastructure
Choose Your Learning Path
DevOps Path
This pathway focuses on breaking down organizational silos by blending software development directly with infrastructure management. Engineers learn to treat infrastructure as code, ensuring that configuration, deployment, and validation are fully automated within continuous delivery pipelines. This path emphasizes velocity, repeatable deployment patterns, and early integration testing to catch systemic bugs before code reaches production environments. It provides the core foundational skills necessary to manage rapid application delivery cycles without sacrificing environment stability.
DevSecOps Path
This trajectory embeds security checks directly into every stage of the automated software development lifecycle rather than treating it as a final review phase. Professionals pursuing this route learn to automate vulnerability scanning, manage secrets securely within containerized environments, and enforce compliance policies as code. By combining operational reliability with strict security guardrails, engineers ensure that fast-moving deployments remain safe from emerging threats. This path is crucial for professionals working in highly regulated industries like finance, healthcare, and government cloud operations.
SRE Path
This specialized track approaches operational puzzles through the lens of software engineering, treating system administration as a software problem. It concentrates heavily on defining precise data metrics, establishing error budgets, and building self-healing automation to minimize human intervention during incidents. Engineers learn how to balance the business demand for rapid feature releases with the absolute necessity of system uptime and performance. This path develops the core skills needed to manage complex distributed topologies and keep large-scale digital platforms online.
AIOps Path
This path introduces artificial intelligence algorithms into infrastructure management to automate anomaly detection, root cause analysis, and event correlation. Engineers study how to feed large volumes of system logs and performance metrics into machine learning engines to predict infrastructure failures before they occur. This training helps minimize alert fatigue by filtering out background noise and pointing on-call teams directly to systemic problems. It represents the future of operating massive, hyperscale systems where human log analysis is no longer practical.
MLOps Path
This discipline focuses on the unique operational challenges of deploying, monitoring, and maintaining machine learning models in production environments. Professionals master data pipeline automation, version control for large datasets, and tracking model performance degradation over time. This path bridges the gap between data science experimentation and dependable, scalable enterprise software execution. It ensures that complex artificial intelligence workloads run predictably, scale efficiently, and deliver accurate business outputs under heavy production demands.
DataOps Path
This pathway applies agile engineering and operational rigor to continuous, high-volume data collection, transformation, and storage pipelines. It teaches data engineers how to automate data quality testing, monitor database performance metrics, and orchestrate complex analytical workflows. By treating data pipelines with the same operational discipline as application code, organizations avoid downstream corruption and analytics downtime. This path is vital for enterprises that depend on real-time data processing to drive live automated business decisions.
FinOps Path
This modern specialty combines cloud engineering with financial accountability to optimize cloud spending across complex enterprise deployments. Engineers learn to track resource utilization metrics, design cost-efficient architectures, and build automated policies that eliminate idle infrastructure. This path ensures that cloud scaling choices are guided by real-time business value rather than guesswork. It empowers engineering teams to take ownership of their infrastructure costs while maintaining high availability and peak system performance.
Role → Recommended Certified Site Reliability Engineer Certifications
| Role | Recommended Certifications |
| DevOps Engineer | Certified Site Reliability Engineer – Professional |
| SRE | Certified Site Reliability Engineer – Professional, Advanced Architect |
| Platform Engineer | Certified Site Reliability Engineer – Professional, Advanced Architect |
| Cloud Engineer | Certified Site Reliability Engineer – Foundation, Professional |
| Security Engineer | Certified Site Reliability Engineer – Professional |
| Data Engineer | Certified Site Reliability Engineer – Foundation |
| FinOps Practitioner | Certified Site Reliability Engineer – Foundation |
| Engineering Manager | Certified Site Reliability Engineer – Foundation, Professional |
Next Certifications to Take After Certified Site Reliability Engineer
Same Track Progression
After completing the core certifications, professionals should focus on deep specialization within the reliability engineering domain. This involves pursuing advanced certifications that focus on specialized topics like advanced kernel tuning, deep eBPF observability, or specialized container network debugging. Advancing within the same track ensures you remain a subject matter expert capable of solving the most difficult infrastructure anomalies an organization can face.
Cross-Track Expansion
Broadening your technical capabilities requires expanding into adjacent tracks like advanced security engineering or cloud cost optimization platforms. Acquiring cross-functional credentials allows you to view infrastructure challenges through multiple lenses, making you an incredibly versatile asset to platform engineering teams. This cross-pollination of skills helps you bridge communication gaps between development, security, operations, and finance departments.
Leadership & Management Track
For engineers looking to transition away from individual technical contribution, moving into the strategic management track is the logical next step. This focus area includes certifications in engineering leadership, agile portfolio management, and strategic technology governance. These credentials prepare you to manage entire engineering departments, build high-performing technical teams, and align infrastructure budgets with long-term corporate goals.
Training & Certification Support Providers for Certified Site Reliability Engineer
DevOpsSchool provides comprehensive, instructor-led training programs that focus on practical, hands-on labs and real-world deployment scenarios for modern engineering professionals. Their curriculum is structured to support enterprise teams looking to upgrade their legacy operational skillsets to cloud-native standards efficiently.
Cotocus specializes in delivering deeply technical bootcamps and customized corporate training tracks designed to bridge skills gaps in complex automated infrastructures. Their practical lab environments closely simulate real-world production incidents, allowing engineers to build confidence under operational pressure.
Scmgalaxy offers an extensive repository of educational resources, community forums, and expert-led tutorials focused on configuration management and deployment pipeline automation. It serves as an excellent reference hub for engineers preparing for rigorous practical examinations.
BestDevOps focuses on delivering highly curated training modules that align directly with contemporary industry requirements and cloud-native architecture best practices. Their instructional design emphasizes production readiness and modern platform engineering techniques.
devsecopsschool addresses the critical intersection of system security and automated operations, providing targeted courses that help teams embed security controls directly into delivery pipelines. Their training ensures security becomes an integrated part of daily operations.
sreschool stands as a dedicated educational platform built entirely around site reliability engineering disciplines, offering structured pathways from introductory concepts up to advanced architectural design. It serves as a primary hub for mastering production resilience.
aiopsschool leads the industry in training engineers to integrate machine learning models and automated anomaly detection systems into traditional monitoring stacks. Their courses prepare professionals to manage high-volume telemetry environments using advanced data analytics.
dataopsschool focuses on bringing operational discipline to data engineering teams, providing specialized education on automating data pipelines and managing distributed database reliability. Their programs ensure data infrastructure remains stable and predictable.
finopsschool provides tailored educational tracks that combine cloud architecture strategies with financial management principles to optimize corporate cloud infrastructure expenditures. Their courses help engineers quantify and manage the financial impact of technical decisions.
Frequently Asked Questions (General)
- What is the primary difference between DevOps and SRE frameworks?DevOps focuses on the cultural shift and pipeline automation required to bridge the gap between software development and operations teams. SRE applies specific software engineering disciplines directly to solving complex operational, scalability, and reliability challenges in production environments.
- How much time does it typically take to prepare for the professional certification?Most candidates with prior operations experience require approximately 30 to 60 days of consistent study and practical lab work to successfully pass.
- Are there any mandatory prerequisites before attempting the foundational exam?There are no formal administrative prerequisites, but a basic understanding of Linux systems administration and command-line networking concepts is highly recommended.
- What is the measurable return on investment for an enterprise supporting this program?Organizations typically experience a significant reduction in mean time to resolution, fewer critical production outdates, and a more resilient deployment velocity.
- Can software developers transition into this specialty without prior operations experience?Yes, developers can successfully transition by using this curriculum to learn infrastructure mechanics, system telemetry, and deployment operations.
- How long does the certification designation remain valid before requiring renewal?The certification credentials remain fully valid for a period of three years, after which professionals complete a renewal assessment.
- Is the examination process strictly theoretical or does it include practical testing?The evaluation includes a mix of conceptual scenarios and practical, hands-on tasks designed to test real-world troubleshooting capabilities.
- How does this certification help professionals working within the Indian IT market?It provides standardized validation that aligns Indian engineering professionals with global enterprise standards, opening up advanced international career opportunities.
- What tools and software frameworks are covered during the course of study?The curriculum focuses primarily on vendor-neutral principles, but utilizes standard industry platforms like Kubernetes, Prometheus, and various terraform utilities for practical exercises.
- How does this program address modern cloud infrastructure environments?The core concepts are built directly around cloud-native, multi-cloud, and hybrid enterprise infrastructure patterns to ensure immediate real-world utility.
- Can an engineering manager benefit from completing the foundational level?Yes, it equips technical managers with the exact vocabulary and structural frameworks needed to build and evaluate modern reliability metrics.
- What strategy is recommended if a candidate fails the initial assessment?Candidates receive a detailed performance breakdown, allowing them to focus on weak domains before reattempting the exam after a cooling period.
FAQs on Certified Site Reliability Engineer
- How does the Certified Site Reliability Engineer program directly address the challenge of alert fatigue in large enterprise monitoring systems?The curriculum teaches engineers to move away from simple threshold-based alerting on random system metrics. Instead, it focuses on building alerts tied directly to service level objectives and customer-facing symptoms, ensuring engineers only get paged for actionable infrastructure emergencies.
- Does this validation framework place a heavy emphasis on coding and software development algorithms?While you do not need to be an expert in complex data structures, it requires a solid proficiency in scripting and automation logic. The program ensures you can write reliable scripts to automate operational tasks and eliminate manual, repetitive toil.
- How does the training curriculum incorporate modern chaos engineering principles within production architectures?The professional and advanced tracks teach candidates how to plan, scope, and safely execute controlled fault-injection experiments. This training focuses on discovering hidden architectural weaknesses before they cause uncontrolled, catastrophic outages in live consumer environments.
- What specific methodologies are taught within this program to handle incident post-mortems?The framework focuses deeply on blameless post-mortem methodologies, teaching professionals how to identify systemic root causes rather than blaming human error. This approach ensures organizations learn from operational failures and continuously improve infrastructure resilience over time.
- How does this certification help platform engineering teams establish accurate error budgets?It provides clear mathematical frameworks to calculate the exact balance between permissible downtime and development speed. This training ensures that product features and operational stability goals are aligned through clear, data-driven engineering guidelines.
- Is this program optimized for single-cloud setups or does it cover complex hybrid environments?The framework focuses on core distributed system principles that apply universally across all infrastructure topologies. This ensures your skills remain highly effective whether your organization operates on AWS, Azure, Google Cloud, or hybrid on-premises setups.
- How does the curriculum handle the automation of legacy systems that lack modern API endpoints?It provides strategies for wrapping legacy infrastructure with automated abstraction layers, modern proxy services, and custom telemetry exporters. This enables engineers to bring older enterprise applications up to modern operational standards without rewriting everything.
- What role does capacity planning play in the advanced tiers of this certification program?The advanced architectural track teaches engineers to use historical telemetry trends and predictive demand modeling to automate resource provisioning. This training ensures that enterprise platforms scale efficiently ahead of traffic surges while keeping cloud expenditures optimized.
Final Thoughts: Is Certified Site Reliability Engineer Worth It?
Investing in professional validation should always be driven by practical utility rather than industry hype. The Certified Site Reliability Engineer designation provides genuine professional value because it focuses on the hard, unglamorous realities of keeping complex distributed systems operational. It moves past generic corporate buzzwords to teach the precise math, engineering logic, and automation patterns needed to protect production revenue.
If your career goal is to stay relevant in a fast-changing market and move into high-impact infrastructure roles, this program provides a clear, reliable blueprint. It changes the way you view software systems, shifting your perspective from simple code deployment to long-term architectural stability. True engineering authority comes from understanding how systems fail and building structures that withstand those failures—skills that this curriculum successfully validates.